问题描述:
在FullNAT在使用过程中,在开启SYNProxy的情况下,采用CURL去连接某个URL,会有偶尔卡顿一下,命令如下:
for i in `seq 1 10000`;do curl -o '/dev/null' -w "%{time_total}:%{time_connect}:%{time_appconnect}:%{time_starttransfer}n" http://192.168.1.100 >> fullnat.txt ; done
100 582 100 582 0 0 54356 0 --:--:-- --:--:-- --:--:-- 58200
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 582 100 582 0 0 54586 0 --:--:-- --:--:-- --:--:-- 58200
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
以上命令偶尔会出现6s左右的超时等待。这个事情很神奇,为什么是6s呢,不是其他数字呢,如果是丢包的话,时间为什么这么固定呢,猜测这可能跟程序的实现有关系?
抓包复现:
我们在FullNAT机器和RealServer机器同时抓包。如下图:
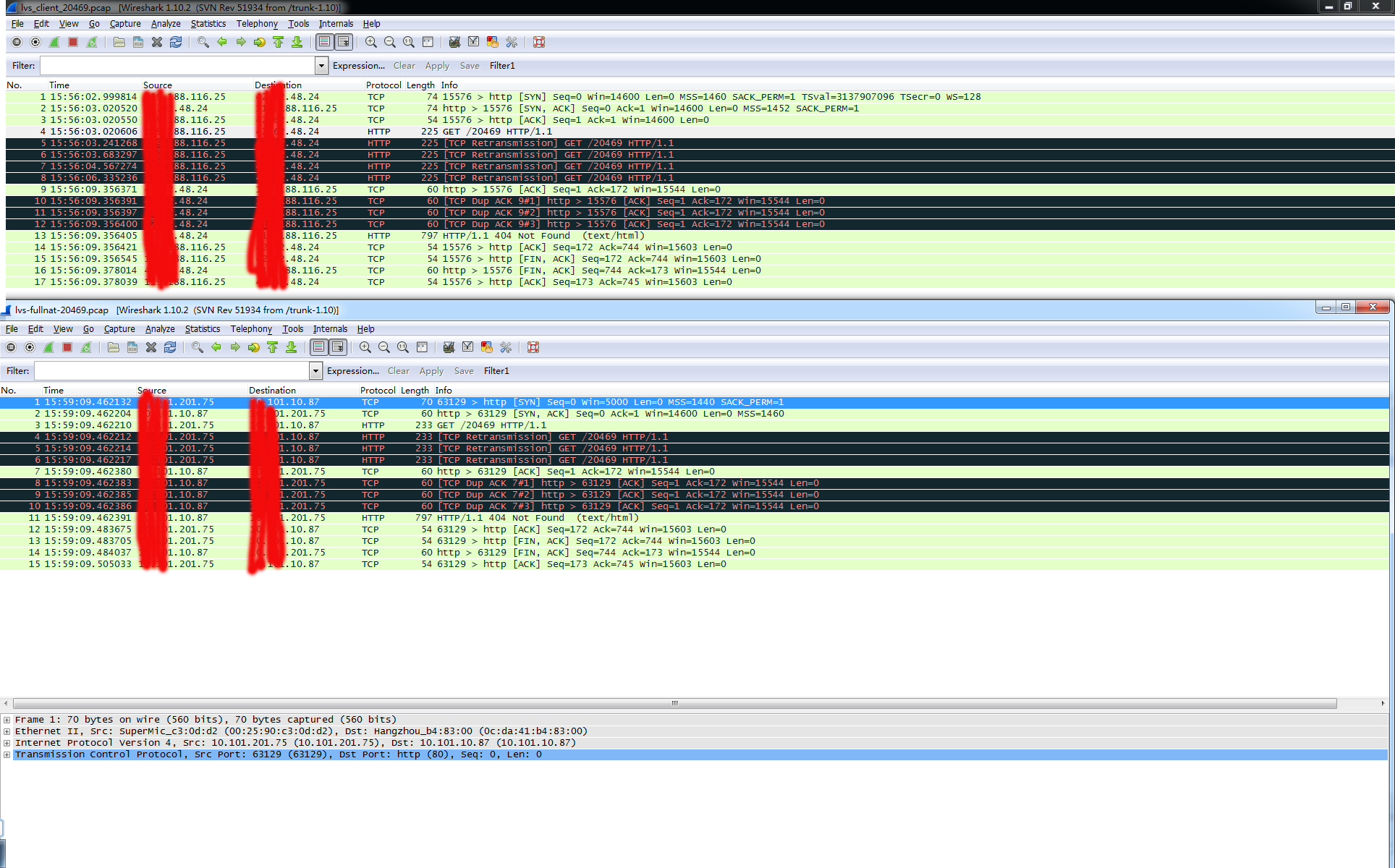
第一张图是在fullnat机器上抓的,是从client到fullnat的包,第二张图在real server上抓的,是从fullnat到real server的包,从图中可以看出,从xx.xx.116.25到xx.xx.48.24,xx.xx.116.25是client,xx.xx.48.24为fullnat的vip,从第一张图中看出,完成了三次握手以后,client就开始请求数据包,但是请求数据包一直没有回应,在超时以后一直进行重发。难道是请求数据包时丢了?我们从real server上的抓包情况可以得到结果。client从03秒(抓包机器时间设置相差3分钟,单秒数是对的)开始发送数据包,但是real server从09秒时才开始3次握手建立连接。建立连接以后,并且将重发的包又转发了一遍。那么,我们从二张图中得出,导致延迟的原因是fullnat和real server建立连接的过程中,第一个syn包丢了或者没有送出来,才导致了这6秒的延时,那么为什么是6s呢,这得从fullnat代码中查看,经过代码搜索,终于找到了蛛丝马迹。
在ip_vs_proto_tcp.c文件中:
1158 int sysctl_ip_vs_tcp_timeouts[IP_VS_TCP_S_LAST + 1] = {
1159 [IP_VS_TCP_S_NONE] = 2 * HZ,
1160 [IP_VS_TCP_S_ESTABLISHED] = 90 * HZ,
1161 [IP_VS_TCP_S_SYN_SENT] = 3 * HZ,
1162 [IP_VS_TCP_S_SYN_RECV] = 30 * HZ,
1163 [IP_VS_TCP_S_FIN_WAIT] = 3 * HZ,
1164 [IP_VS_TCP_S_TIME_WAIT] = 3 * HZ,
1165 [IP_VS_TCP_S_CLOSE] = 3 * HZ,
1166 [IP_VS_TCP_S_CLOSE_WAIT] = 3 * HZ,
1167 [IP_VS_TCP_S_LAST_ACK] = 3 * HZ,
1168 [IP_VS_TCP_S_LISTEN] = 2 * 60 * HZ,
1169 [IP_VS_TCP_S_SYNACK] = 30 * HZ,
1170 [IP_VS_TCP_S_LAST] = 2 * HZ,
1171 };
1161行中的IP_VS_TCP_S_SYN_SENT代表了当fullnat和real server 的第一syn包发送失败以后超时重传的时间,如果synproxy在第二个三次握手时,第一个syn包发送失败或者被丢弃,重发的时间间隔为3s,这就解释了为什么是超时6s,估计是fullnat发送了3次syn包,但是前两次都丢弃了,或者fullnat前两个根本没有发包。从抓包的结果来看,fullnat确实没有发送前2个包,我们进一步在fullnat中打日志查看。在ip_vs_conn.c文件中,对超时的连接有处理:
881 static void ip_vs_conn_expire(unsigned long data)
...
901 /*
902 * Retransmit syn packet to rs.
903 * We just check syn_skb is not NULL, as syn_skb
904 * is stored only if syn-proxy is enabled.
905 */
906 spin_lock(&cp->lock);
907 if (cp->syn_skb != NULL && atomic_read(&cp->syn_retry_max) > 0) {
908 atomic_dec(&cp->syn_retry_max);
909 if (cp->packet_xmit) {
910 tmp_skb = skb_copy(cp->syn_skb, GFP_ATOMIC);
911 cp->packet_xmit(tmp_skb, cp, pp);
912 }
913 /* statistics */
914 IP_VS_INC_ESTATS(ip_vs_esmib, SYNPROXY_RS_ERROR);
915 spin_unlock(&cp->lock);
916 goto expire_later;
917 }
918 spin_unlock(&cp->lock);
以上的代码意思就是说,如果重发的次数没有超过最大重发次数(默认是3次),就进行重发。对packet_xmit函数进行了跟踪,发送在超时的时候,packet_xmit函数确实进行了调用,而且调用了成功了,但是抓包却没有抓到。因此估计是在fullnat下面的某个环节,内核把数据包给丢了,具体是在哪里丢的,由于涉及内核东西较多,我暂时还没有追踪。
改进方法
由于synproxy的第二个三次握手时,没有采用tcp的重传机制,而是采用了简单的3s重传机制,当有丢包时,会出现3s,6s,9s等不等的延迟。消除此现象的方式大概有几种:
1,关掉synproxy,通过测试发现,关掉synproxy的情况会出现某些请求的等待,但出现的概率降低,同时等待的时间大都小于3s
2,改造synproxy的重复机制,使其和tcp的重传机制一样,这也是小米目前采用的方式,修改如下:
882 static void ip_vs_conn_expire(unsigned long data)
883 {
884 struct ip_vs_conn *cp = (struct ip_vs_conn *)data;
885 struct sk_buff *tmp_skb = NULL;
886 struct ip_vs_protocol *pp = ip_vs_proto_get(cp->protocol);
887 /* fix synproxy timeout add by panxiaodong@xiaomi.com */
888 int retry_idx = 0;
...
904 /*
905 * Retransmit syn packet to rs.
906 * We just check syn_skb is not NULL, as syn_skb
907 * is stored only if syn-proxy is enabled.
908 */
909 spin_lock(&cp->lock);
910 if (cp->syn_skb != NULL && atomic_read(&cp->syn_retry_max) > 0) {
911 atomic_dec(&cp->syn_retry_max);
912 /* fix synproxy timeout add by panxiaodong@xiaomi.com */
913 retry_idx = sysctl_ip_vs_synproxy_syn_retry - atomic_read(&cp->syn_retry_max);
914 cp->timeout *= (1<<retry_idx);
915
916 if (cp->packet_xmit) {
917 tmp_skb = skb_copy(cp->syn_skb, GFP_ATOMIC);
918 cp->packet_xmit(tmp_skb, cp, pp);
919 }
从测试效果来看,也能降低延迟等待,但是并不能消除此问题。
3,修改packet_xmit函数,从追踪的过程中,发现packet_xmit函数已经调用成功,但是包并没有真正发出,估计是内种某个过程丢了,packet_xmit发送宏如下:
243 #define IP_VS_XMIT(pf, skb, rt)
244 do {
245 (skb)->ipvs_property = 1;
246 skb_forward_csum(skb);
247 NF_HOOK(pf, NF_INET_LOCAL_OUT, (skb), NULL,
248 (rt)->u.dst.dev, dst_output);
249 } while (0)
具体为什么会丢包,就不得知了,可以将NF_HOOK接口替换成更底层的发送接口,使用dev_queue_xmit函数可能能解决次问题,synproxy中就使用了此函数,但是我还没有去验证。
总结:
在fullnat使用过程中,出现顿卡的问题比较影响使用,采用方法二能够降低顿卡现象,但是没有完全解决。或许替换NF_HOOK能完全解决此问题,这个需要与 fullnat的作者[吴佳明等]沟通。测试过程中发现pps越高,顿卡现象越严重,在pps没有超过100w时,基本不会出现顿卡现象。后续会把fullnat在各种环境中的表现,总结一下,再分享出来。
转载请注明:爱开源 » lvs FullNAT顿卡问题原因追查